
Unsupervised Class Generation to Expand Semantic Segmentation Datasets
A synthetic data pipeline using Stable Diffusion and SAM to add missing semantic classes for unsupervised domain adaptation in semantic segmentation.

My doctoral research at Universidad Autónoma de Madrid / VPULAB focused on synthetic data for computer vision: how to generate it, evaluate it, and use it to improve models when real-world labels are scarce or difficult to obtain. The work below spans published projects in semantic segmentation, spacecraft pose estimation, visual odometry, and depth-related tasks using CARLA, Unity, procedural generation, and generative models.
A synthetic data pipeline using Stable Diffusion and SAM to add missing semantic classes for unsupervised domain adaptation in semantic segmentation.
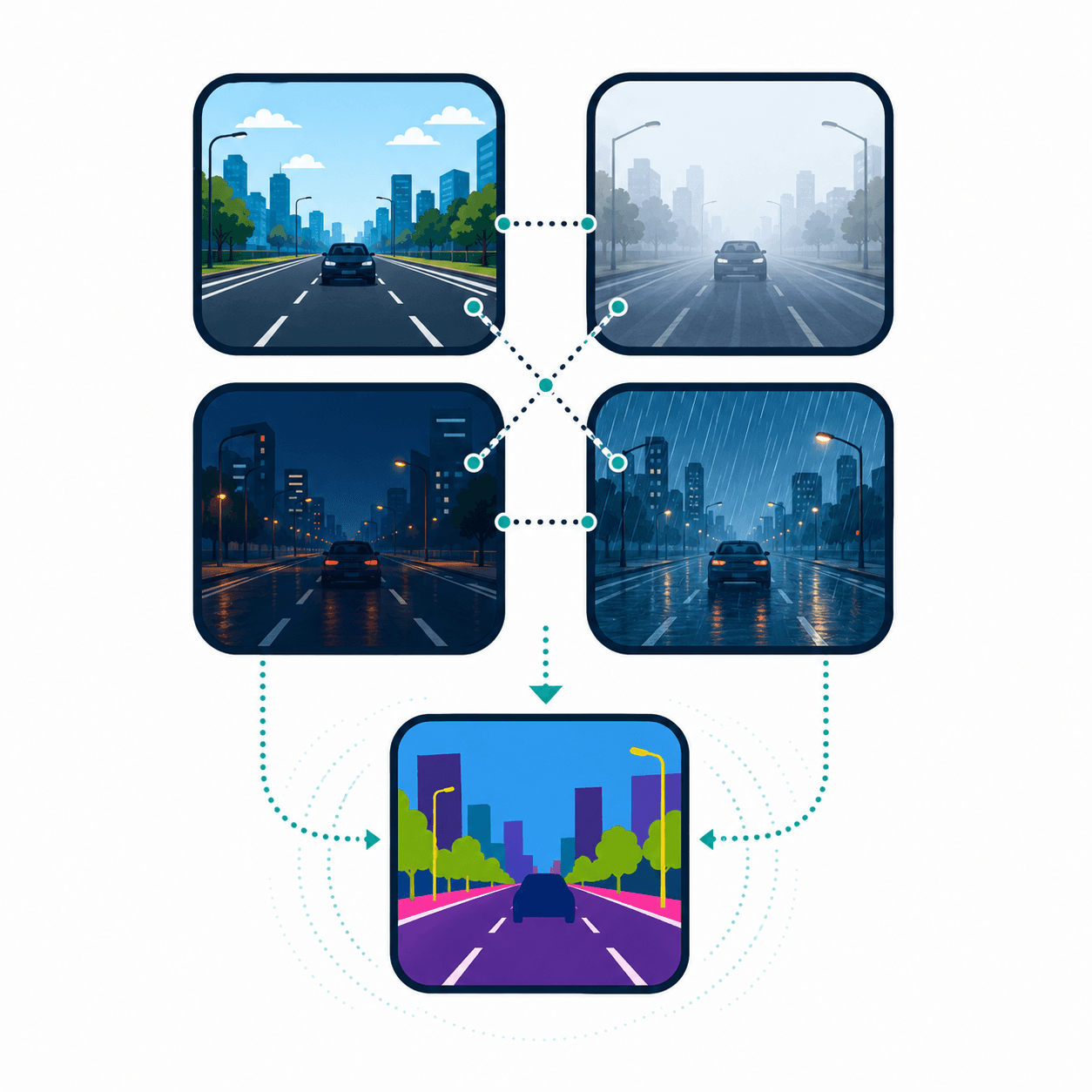
A CARLA-generated semantic segmentation dataset with pixel-aligned appearances for feature alignment. The dataset improves UDA and domain generalization performance without pseudo-labeling.

Built in Unity, SPIN is a custom data pipeline for orbital environments. It simulates high-fidelity spacecraft navigation imagery. Using this synthetic data reduced our pose estimation error by up to 65% compared to models trained only on standard datasets.

A synthetic LiDAR dataset generated with a custom CARLA modification for training and evaluating semantic segmentation models. Published at ICIP 2024.
I developed a reinforcement learning pipeline to measure the impact of visual abstraction on agent training. Using Super Mario as an evaluation environment, the system demonstrated that replacing raw RGB inputs with semantic segmentation masks significantly reduces convergence time. This research was published in the Multimedia Tools and Applications journal.